 발전기금
발전기금


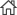
머신러닝과 토픽모델링을 활용한 한국 고문서 복원과 해석
- 소셜이노베이션융합전공
- 조회수294
- 2021-07-12
머신러닝과 토픽모델링을 활용한 한국 고문서 복원과 해석

영국의 역사학자이자 외교관이었던 E. H. 카는 『역사란 무엇인가』에서 "역사란 과거와 현재와의 끊임없는 대화다"라고 말했다. 과거의 역사는 단순히 그것이 과거에서 머무르는 것이 아니라 현재까지도 여러 혜안을 제시해줄 수 있으며, 따라서 역사적 기록을 살펴보는 것은 다양한 분야의 역사적 사건을 확인하고 다양한 측면에서 해석할 수 있는 여지를 제공한다. 그러나, 이러한 고문서들은 한자나 라틴어 등 당시의 주류 언어로 작성되었기 때문에 해석하기가 어렵고 일반인들이 그 내용을 확인하는 것이 불가능에 가깝고, 시간이 지남에 따라 보존의 문제로 인해 훼손된 부분들이 발생하기 때문에 여러 복잡한 과정을 거치지 않는 이상 충분히 활용하기 매우 까다롭다.
저자들은 이러한 문제를 해결하기 위해, 뉴럴 네트워크를 활용하여 언어 모델링, 특히 훼손된 내용의 복원 및 신경망 기계 번역 작업을 수행했다. 또한, 기록이 담고 있는 역사적 사건을 효율적으로 포착하기 위해 번역된 내용을 바탕으로 토픽 모델링을 적용했다. 연구자들은 한국의 대표적인 역사서라고 할 수 있는 조선왕조실록과 승정원일기를 분석자료로 활용했다. 두 사서는 각각 5천만 자와 2억 4천 3백만 자로 이루어져 세계에서 가장 방대한 기록물로 인정받고 있다.
연구자들은 과거 기록을 복원 및 변환하기 위한 멀티태스킹 학습과 함께 어텐션 메커니즘을 기반으로 모델을 설계했다. 모델링을 통해 승정원일기에서 번역되지 않은 모든 문장을 번역했으며, 번역 결과에 대한 토픽모델링을 적용하여 의미 있는 과거 사건을 추출하는 과정을 거친다. 모델 학습을 위해 국사편찬원이 제공한 현재까지 번역된 조선왕조실록과 승정원일기 대부분의 문서를 수집했다(수집 결과 조선왕조실록이 약 25만 개, 승정원일기가 140만 개 문서로 확인된다). 모델링 단계에서는 20000개의 문장이 선택되었다.

실제 사람도 번역하기 어려운 고유명사를 제외하면 문서 복원은 상당히 높은 정확도를 보여주었다
분석에 활용한 모델의 정확도는 세부적인 파라미터나 기법에 따라 다소간의 차이는 있으나 최종적으로는 89%의 정확도를 보여주었다. 다만 고유명사의 경우 다양한 배경지식을 요하며 전문가도 정확한 번역이 쉽지 않기 때문에 200개의 샘플을 이용하여 모델 성과를 정량적으로 측정하였고 그 결과 평균 상위 10개 정확도는 89%보다 큰 전체 정확도보다 훨씬 낮은 8.3%로 나타났다. 기계 번역의 경우 중한 기계 번역기를 사용하여 한자-한국어 번역 작업의 품질을 테스트했다. 구글 번역이 널리 쓰이고 있으나 당시의 한자 문법이 지금의 중국어 활용과 많이 달라 번역이 거의 이루어지지 않았기 때문에 샘플링을 통해 번역한 결과 정치, 사회적 문제뿐만 아니라 자연현상에 대한 내용도 확인할 수 있었다(실제로 전근대에서 중국과 한국에서 자연현상은 기후, 점궤에 중요한 단서를 제공하곤 했다).
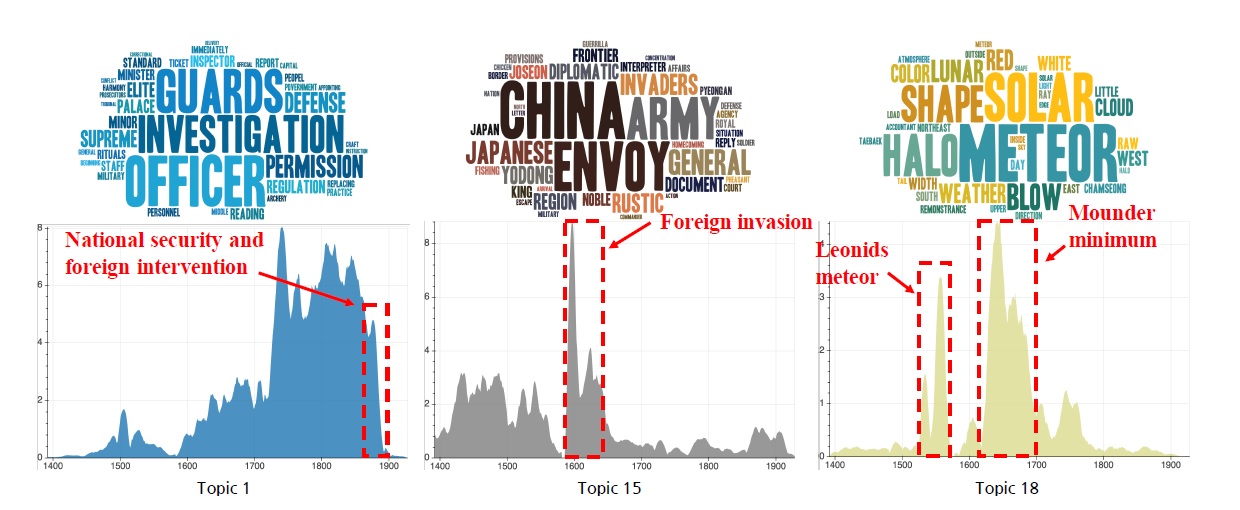
국가 안보, 전쟁과 관련된 토픽의 추이는 실제 역사와 비슷한 흐름을 보여주었다
번역 내용에 대한 토픽모델링 결과 시기별 이슈에 따라 다양한 토픽이 포착되었다. 연구자들은 특히 국가안보나 외침과 관련하여 1592년 임진왜란 이후부터 1882년 임오군란에 이르기까지 국가안보와 관련된 토픽의 비중이 늘어난 점, 17세기 초반 임진왜란과 관련된 토픽이 크게 증가한 점 등을 그 예로 들었다.
< 연구 함의 >
연구자들은 본 연구 결과를 통해 실제 고문서 번역 작업을 수행하는 분석가들의 작업을 지원할 수 있을 뿐만 아니라, 일반인들이 특별한 영역 지식 없이도 문서를 탐색할 수 있는 방향을 모색해볼 수 있다는 것을 연구의의로 제시했다. 또한 한국어 번역이 좀 더 용이하게 진행된다면 한국의 고문서를 향후 다른 언어권으로 번역하고 소개할 수 있는 장점 또한 내포하고 있다.
< 자료 원문 >
Kang, Kyeongpil, et al. "Restoring and Mining the Records of the Joseon Dynasty via Neural Language Modeling and Machine Translation." arXiv preprint arXiv:2104.05964 (2021).



