 발전기금
발전기금


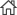
재난재해 데이터셋 Incidents의 구축
- 소셜이노베이션융합전공
- 조회수284
- 2021-09-06
재난재해 데이터셋 Incidents의 구축

지진, 홍수, 산불 등 자연재해에 대응하는 것은 현장에 파견되는 응급구조대원과 분석가들이 수행하는 고된 과제 중 하나이다. 자연재해나 긴급 상황을 신속하게 감지하는 것은 최대한 빠른 조치를 통해 인명 및 재산피해를 막는다는 점에서 매우 중요하다. 그러나 이를 위한 정보 수집은 사람이 직접 검수해야 하는 동시에 전문가의 평가가 필요한 경우가 많기 때문에 노동 집약적이고 비용이 많이 든다는 문제가 있다. 또한 재난들이 발생하는 양상이 동일하지 않기 때문에 이러한 데이터를 어떻게 구축할 것인지에 대한 문제 또한 제기될 수 있다.
MIT, 하마드 빈 칼리파 대학교, 오베르타 대학(카탈루냐 소재)의 연구진 등이 참여한 본 연구에서는 플리커나 트위터 등 SNS 상에서 공유된 사고, 자연재해의 사진을 바탕으로 구축한 대규모 데이터셋인 ‘인시던츠(Incidents)’ 를 소개하고 있다. SNS와 자연재해 대응을 연결한 연구는 이전에도 다양하게 수행되었다. 그러나 비전문가인 일반 사용자들이 올리는 사진에는 노이즈가 발생할 수 있고, 아직까지는 딥러닝 모델을 수립하기 위한 충분한 양의 이미지를 확보하지 못했다는 문제가 있다.
연구진들은 대규모 데이터셋 구축을 위해 해변, 교량, 숲, 집 등의 레이블과 위치 정보가 포함된 110만 개의 이미지를 수집하여 43개의 사고와 자연재해 범주로 나누어 분류했다. 110만 여개의 이미지는 사고나 재난으로 레이블링한 447,000개 이미지와 이들과는 무관한 것으로 레이블링된 697,000개의 이미지로 나뉜다. 서로 상반되는 상황을 학습해야 벽난로와 집 화재, 자전거가 사고 등으로 망가진 것과 아닌 것을 구별할 수 있기 때문이다.
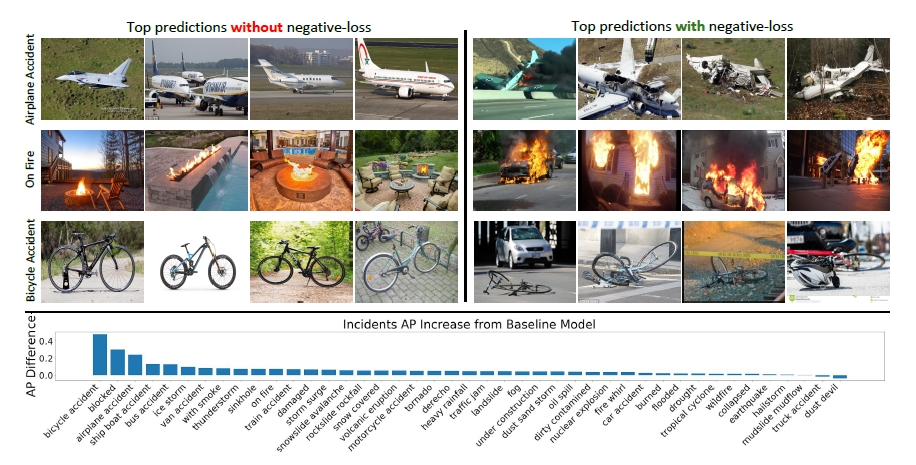
최초의 이미지 데이터는 구글 이미지 검색을 통해 약 350여 만개에 달하는 이미지를 수집했다. 수집된 이미지의 분류 작업을 위해 아마존에서 제공하는 메카니컬 터크(Mechanical Turk: 과제 작성자와 수행자를 크라우드 소싱 서비스를 통해 연결해주는 플랫폼으로, 해결해야 하는 과제를 가진 요청자가 과제를 메카니컬 터크에 올리면, 전세계에 작업자로 등록된 사람들이 실시간 자발적으로 접속해 과제를 수행하는 과정)를 통해 레이블을 붙였고, 다양한 작업자들이 수행한 내용을 확인해 85% 이상의 정확도를 얻은 이미지만 수집했다.
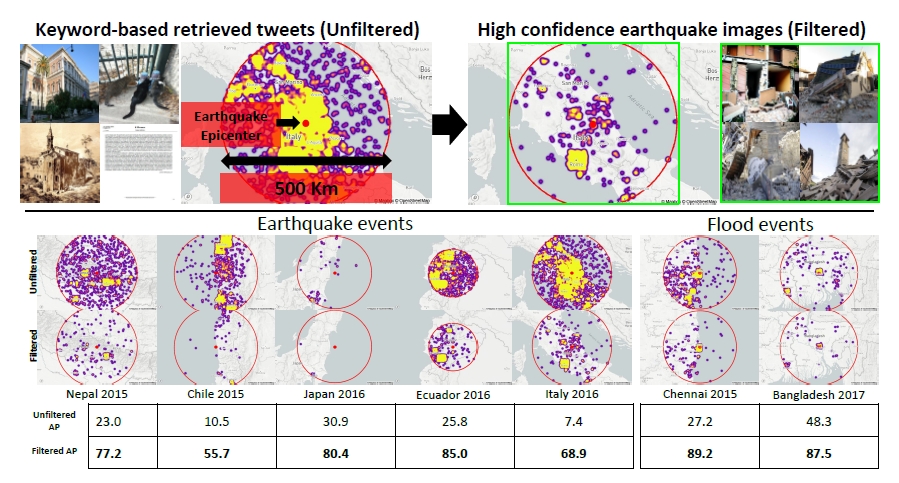
연구자들은 확보한 데이터를 CNN을 이용해 학습 효과를 판단했고 이를 검증하기 위해 지진 5건, 홍수 2건과 관련된 트위터 사진 90만 장을 인식한 결과, 지진은 74%, 홍수는 89%의 정확도를 얻었다고 한다. 또한 4,000만 장의 위치 정보가 있는 플리커 이미지를 대상으로 한 테스트에서는 지진이나 화산 폭발에 의한 긴급 상황을 탐지하게 했으며, 이를 통해 지진이나 화산 활동의 위치를 알 수 있었다고 한다.
연구자들은 사고 탐지를 위한 어떤 데이터셋보다 더 크고, 완성도가 높고, 다양하다고 주장하고 있다. 특히 이 데이터셋은 실제 상황을 담고 있어서 견고한 모델을 학습시키는 데 사용할 수 있음을 강조한다.
< 자료 원문 >
Weber, Ethan, et al. "Detecting natural disasters, damage, and incidents in the wild." European Conference on Computer Vision. Springer, Cham, 2020.



