 발전기금
발전기금


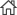
데이터 기반의 난민 정착지 설정으로 난민 고용률을 향상시키는 알고리즘 연구
- 소셜이노베이션융합전공
- 조회수450
- 2021-02-01
데이터 기반의 난민 정착지 설정으로 난민 고용률을 향상시키는 알고리즘 연구

본 논문은 기계학습 접근 방식을 사용하여 난민을 지리적으로 배치해 전체 고용률을 최적화하는 알고리즘을 개발한 연구이다. 선진국 정부들은 난민 위기 심화로 인해 난민 개인과 가족을 사회 공동체에 재정착 시킬 방법을 찾을 필요가 요구되는 상황이다. 난민들을 새로운 환경에 정착시키는 데 있어서 가장 중요한 요소는 크게 지정학적 맥락, 인구학적 요소, 그리고 이 두 요소가 결합되어 나타날 수 있는 시너지 효과이다. 그러나 현재 난민을 수용하는 국가들에서는 이 두 요소의 시너지 효과는 충분히 고려하고 있지 않다. 또한 기존의 난민 정착지에 관한 연구들은 이론적인 설득력은 있었지만, 난민들에 대한 체계적인 데이터의 부족과 정치적인 영역에서의 협력 필요성 등 이를 실행시키는 데 실질적인 장벽이 존재했다.
 어떠한 난민들이 어디에 정착하느냐에 따라 고용확률이 크게 달라질 수 있다
어떠한 난민들이 어디에 정착하느냐에 따라 고용확률이 크게 달라질 수 있다
연구자들은 난민 고용이 난민들을 사회 내로 통합될 수 있는 가장 중요한 요소로 보고, 실제 난민 데이터를 활용하여 이러한 시너지 효과를 반영하여 고용률을 높일 수 있는 알고리즘을 개발했다. 이를 위해 연구자들은
1) 모델링(Modeling): 어떠한 측정가능한 형태로서 예측할 수 있는 결과를 도출하는 기계학습 모델을 구축한다. 이를 위해 실제 난민들에 관한 기본적인 정보(출신지, 성별, 나이, 교육수준 등)을 고려하여 기계학습을 진행했다.
2) 맵핑(Mapping): 모델링 단계에서 반영하는 자료는 난민 개개인에 대한 자료지만 실제 난민들이 지역 내에 정착할 때는 가족 단위로 구성되는 경우가 많기 때문에 이를 반영할 수 있는 과정이 필요하다. 연구자들은 이에 대한 기준으로 적어도 한 명의 난민들이 해당 장소에서 일자리를 찾을 수 있는 예측 확률을 활용했다.
3) 매칭(Matching): 기계학습된 모델과 맵핑 단계로 실제 지역(미국은 에이전시가 구분한 지역, 스위스의 경우 주(canton)를 기준)과 연결하면서 최적화된 결과를 도출하는 알고리즘을 최종적으로 구성하는 단계이다. 연구자들은 난민들에 대한 정보를 수집하는 단계에서는 확인할 수 없는 여러 기준과 제약 조건을 수용할 수 있는 유연한 알고리즘을 만들고자 했다.
이 3단계를 거쳐 최종적인 알고리즘을 구축했다. 본 연구에서는 서로 다른 형태의 난민 이주 정책을 시행하고 있는 미국과 스위스에서 자료를 확보하였으며, 미국의 경우 미국에서 가장 큰 난민 이주 에이전시 중 한 곳에서 2011년 일사분기부터 2016년 삼사분기까지 33,782명, 스위스에서는 스위스 이민국 기준 1999년에서 2013년까지 22,159명의 자료를 데이터로 활용했다.
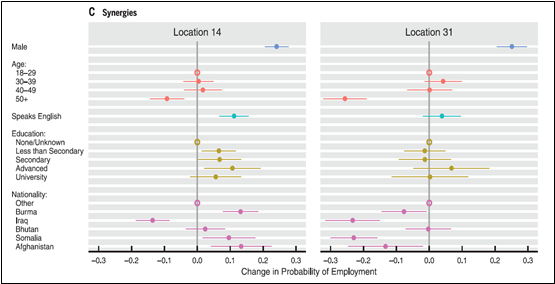
기계학습 알고리즘은 실제 정책과 비교하여 전반적으로 우수한 고용률을 보여주었다 (미국 사례)
위 그래프는 미국 에이전시에서 제공한 데이터를 바탕으로 알고리즘을 돌린 결과를 보여주고 있다. 좌측의 그래프는 경험적 누적 분포 함수(Empirical Cumulative Distribution Functions)로 분석 결과를 제시하고 있는데 ‘고용확률이 같거나 낮은 난민 비율(Fraction of Refugees with Equal or Lower Predicted Probability of Employment)’이 알고리즘 결과가 실제 정책으로 기반한 결과보다 더 낫다는 것을 보여준다(고용확률이 같거나 낮은 난민 비율에 실제 정책을 기반으로 한 곡선이 알고리즘 분석 결과보다 더 가깝게 분포하는 것을 볼 수 있다). 이를 지역별로 확인한 우측의 그래프 역시 대부분의 지역에서 현 정책 기반보다 시너지 효과를 투입한 알고리즘이 더 나은 고용률을 보여주고 있음을 암시한다.
이러한 방식을 난민들의 정보를 바탕으로 고용률과 관련한 알고리즘을 돌린 결과, 현재 난민 배정 정책을 바탕으로 모델링한 결과와 비교하여 난민 고용 결과에서 미국과 스위스 모두 평균 약 40%에서 많게는 70%까지 증가하는 결과를 보여주었다. 난민 이주를 국가가 직접 관리하지 않는 미국과 이민국이 직접 난민 이주를 관할하는 스위스 양국은 난민 정착 제도가 서로 다른 형태를 지니고 있고, 미국 자료는 단기간의 자료를 통한 즉각적 고용, 스위스는 장기간의 자료를 활용했기 때문에 장기고용 결과를 알고리즘에 반영하였는데도 두 곳 모두에서 실제 정책보다 높은 고용률을 보여주었다는 점은 유의미한 결과라 할 수 있다.
< 연구 함의 >
본 연구는 1) 실제 데이터들이 내포하고 있음에도 포착하지 못했던 난민들의 정보와 지역 간의 시너지 효과에 주목하여 이를 알고리즘에 반영했고 2) 실제 데이터를 기반으로 했기 때문에 연구로 구축된 알고리즘을 바로 정책에 적용할 수 있어 추가적인 시간이나 비용이 들지 않는다는 점, 특히 3) 유연한 알고리즘을 만들어 정책 입안자들이 각 지역이나 국가의 특성에 맞게 알고리즘을 수정하여 실질적인 대안 및 정책 도입이 가능하다는 점에서 주목할 만하다.
< 자료 원문 >
Bansak, K., Ferwerda, J., Hainmueller, J., Dillon, A., Hangartner, D., Lawrence, D., & Weinstein, J. (2018). Improving refugee integration through data-driven algorithmic assignment. Science, 359(6373), 325-329.
- 이전글
- 이전글이 없습니다.



