 발전기금
발전기금


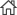
머신러닝, AI는 탄소중립에서 자유로운가?
- 소셜이노베이션융합전공
- 조회수378
- 2021-06-03
- Energy and Policy Considerations for Deep Learning in NLP.pdf
- Carbon Emissions and Large Neural Network Training.pdf

탄소중립, 탄소발자국(직간접적으로 내뿜은 온실기체의 총량)을 줄이기 위한 각국 정부와 글로벌 기업들의 활동이 분주하다. 한국은 온실가스나 탄소중립이 국제적 의제로 등장했을 때부터 이에 대한 준비를 시작하여 2014년 「2020년 국가 온실가스 감축목표 달성을 위한 로드맵」을 시작으로, 2016년 「2030년 국가 온실가스 감축목표 달성을 위한 기본 로드맵」, 2018년 이에 대한 개정안을 발표하고 이로 인해 발생할 수 있는 산업구조, 노동시장의 변화 등과 관련하여 간담회를 개최하는 등 각계의 의견을 수렴하기 위해 노력 중이다.
그렇다면 최근 각광받고 있는 AI 산업에서의 탄소배출은 어떠한가? 구글은 2020년 9월 회사 설립 이후 구글의 이름으로 발생시키는 내뿜은 모든 온실가스를 제거했다고 발표했으며 2030년까지 재생에너지로만 운영되는 데이터센터와 사무실을 계획하고 있다고 밝혔다. 애플 역시 2018년 캘리포니아 쿠퍼티노에 재생에너지로만 운영되는 신사옥을 건립하고 재활용과 친환경에너지를 이용한 제품 생산 계획을 소개한 바 있다.
그렇다면 AI나 머신러닝 기반의 첨단 산업은 탄소 중립에서 자유로운가? 신산업이 기존의 산업을 대체하거나 혁신하면서 환경오염의 개선에 기여하는 경우가 많고, 중공업과는 IT분야는 다른 산업과는 달리 부산물을 남기지 않는다는 점에서 친환경적이라고 할 수 있다. 그러나 머신러닝의 효율성, 정확도를 높이기 위해 상당한 에너지 소비를 필요로 하는 대규모의 서버를 필요로 하고 그러한 서버에서 운용되는 결과로 상당량의 탄소가 배출되는 것이다. 최근 연구결과에서도 머신러닝이나 AI의 활용이 확산될수록 이로 인한 탄소 배출은 무시할 수 없는 수준임이 나타나고 있다.
스트러벨 등(Strubell et al., 2019)의 연구에 따르면 NAS(Neural Architecture Search) 모델 학습의 경우 배출되는 탄소는 약 284톤이라고 밝혔다. 인간이 1년에 약 5톤의 탄소를 배출하는 것으로 알려져 있는데 NAS자연어 처리 모델 학습에 인간의 약 57년치 탄소가 발생하는 것이다. 한편, GPU 활용을 포함한 BERT의 학습 과정에서 배출되는 탄소량은 652㎏으로 나타났다. 패터슨 등(Patterson et al., 2021) 구글 소속 연구팀과 UC 버클리 소속 연구진은 최근 활발하게 쓰이고 있는 T5, Meena, G-Shard, Switch, Transformer, GPT-3 등 대표적인 AI 모델의 에너지 사용량과 탄소 발자국 추정치를 공개했다. 연구팀은 해당 추정치를 바탕으로 AI의 기후 영향을 완화 방안 관련 논문을 발표했다. GPT-3가 학습 과정에서 발생시키는 이산화탄소의 양은 대략 552톤으로, 1년간 120대의 승용차를 운전할 때 생산되는 양과 같은 수치이다. 또한 구글 챗봇 Meena는 1년간 17개의 가정에 공급되는 전력량과 같은 96톤의 이산화탄소를 발생시킨다고 발표했다.
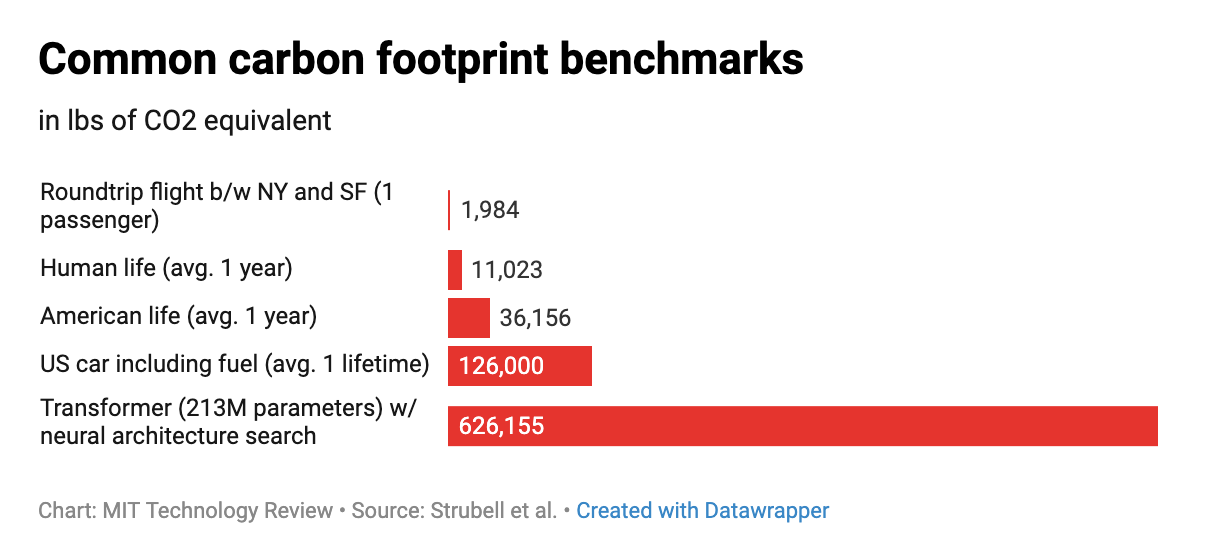
저자들은 1) 알고리즘을 어떻게 구성하느냐에 따라, 2) 머신러닝을 구현하는 서버 혹은 데이터센터의 위치, 3) 데이터센터의 인프라 구성 방식에 따라 탄소 발생량을 줄일 수 있다고 주장했다. 특히 상기한 방식을 모두 고려한 모델일 경우, AI 알고리즘을 훈련하는 데 드는 탄소 발자국을 100배에서 최대 1,000배까지 줄일 수 있다고 한다. 석탄을 주로 쓰는 인도에서 재생 가능 전력 위주인 핀란드로 데이터 센터를 이동할 경우, 탄소 발생량을 약 10배~100배가량 줄일 수 있다. 또한 새로운 하드웨어나 알고리즘의 교체만으로도 가시적인 절감 효과를 발생할 수 있다고 보았다.
한편, 이러한 연구결과는 지속 가능한 AI 시스템이 우선 사항이 된다면 이는 일종의 ‘사다리 걷어차기’와 같은 효과를 불러와서 거대 IT 기업의 입지를 더욱 공고하게 만들 수 있다. 데이터센터의 이동과 같이 막대한 자금을 필요로 하는 사업의 경우 구글, 아마존과 같은 회사처럼 전 세계에 수십 개의 데이터 센터를 보유하고 있는 경우 새로운 데이터 센터 구축이나 입지 변경이 다소 자유롭기 때문이다. 또한, 글로벌 기업이 과연 AI 탄소 배출 절감에 얼마만큼 협조적일 것인가에 대한 문제도 존재한다. 구글은 상기한 바와 같이 본사와 관련된 온실가스 제거 노력에 힘쓴 동시에 대규모 자연어 처리 모델이 낳을 수 있는 환경적 문제에 관련된 논문을 발표한 AI 윤리팀 대표 게브루(Timnit Gebru) 박사를 해고하여 논란이 된 바 있다.
출처1: Strubell, Emma, Ananya Ganesh, and Andrew McCallum. "Energy and policy considerations for deep learning in NLP." arXiv preprint arXiv:1906.02243 (2019).
출처2: Patterson, David, et al. "Carbon Emissions and Large Neural Network Training." arXiv preprint arXiv:2104.10350 (2021)



