 발전기금
발전기금


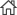
자연어 처리(NLP) 기법 소개
- 쇼셜이노베이션융합전공
- 조회수920
- 2021-02-22
자연어 처리(Natural Language Processing)
인공지능 기술이 발전하면서, 사람과 비슷한 수준으로 말하거나 텍스트를 보여주는 기기가 등장하고 있습니다. 컴퓨터가 사람의 말을 알아들을 수 있도록 하는 기반은 ‘자연어 처리 (Natural Language Processing) 기술’입니다.
자연어 처리는 자연어 분석, 자연어 이해, 자연어 생성 등으로 나뉩니다. 자연어 분석은 문법에 따라 자연어를 쪼개는 것을 말하며, 자연어 이해는 컴퓨터가 자연어로 주어진 입력에 따라 동작하게 하는 기술이며, 자연어 생성은 동영상이나 표의 내용 등을 사람이 이해할 수 있는 자연어로 변환하는 것입니다.
자연어처리는 기계가 사람의 언어에 대해 처리하는 계산적 기술 (Computational Techniques)의 집합이라고 할 수 있습니다. 이러한 자연어 처리 (NLP)의 세부분야로는 감정분석, 번역, 음성인식, 질의응답, 구문분석 등이 있습니다.

출처: 구글이미지
자연어처리 방법으로 많이 사용되고 있는 Topic Modeling에 대해 살펴보겠습니다. Topic Modeling (토픽모델링)이란, 문서 가운데 연관된 단어들을 묶어서 주제 분포를 만들어주고, 문서별로 주제가 얼마나 포함되어있는지 계산해주는 것을 말합니다. 토픽모델링의 기법은 LDA, LSA, deep learning-based lda2vec 등 다양하게 사용되고 있는데 대표적인 기법은 LDA (Latent Dirichlet Allocation)이 사용되고 있습니다.
LDA 기법은 사람들의 각 관심사와 관련된 ’토픽‘이 무엇인지 파악하는지 알 수 있게하는 접근법이라고 이해하면 됩니다.

출처: 구글이미지
주어진 문서 집합에서, 각 단어에 대해 비슷한 문맥에 나타난 단어의 벡터와 유사한 벡터를 갖도록 만들어진 결과를 자연어처리로 표현하는 것을 Word Vectors 혹은 Word Embedding이라고 합니다. 이러한 Word Vectors의 대표적인 표현 방법이 Bag of word, TF-IDF, Word2Vec 등 여러 가지가 있으며, 간단한 개념을 살펴보고자 합니다.
Bag of word 모델은 말 그대로, 주머니에 단어를 그냥 넣은 것과 같이 문서 내에 존재하는 모든 유니크한 단어수가 벡터의 차원이 되어 고차원의 공간이 되는 것을 말합니다. 이 기법은 단순이 단어의 빈도수에 의존하기 때문에 단어의 빈도수가 높다고 반드시 중요하다고 볼 수 없는 문제가 발생합니다. 이를 해결하기 위해 TF-IDF (Term frequency – inverse document frequency)라는 개념이 등장합니다. IDF를 구하기 위해서는 총 문장의 개수를 단어가 출현한 문장이 개수로 나누어 계산합니다. 즉, 한 단어가 문서 전체에서 얼마나 공통적으로 나타나는지를 나타내는 값을 말합니다. 전체 문서의 수를 해당 단어를 포함한 문서의 수로 나눈 뒤, 로그를 취해 얻을 수 있습니다.
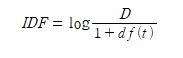
TF-IDF의 수학적 정의는 단어 빈도와 역문서 빈도의 곱이라 할 수 있고 여러 문서가 있을 때, 특정 문서 안에서 특정 단어가 어느 정도 중요한 의미를 갖는지 수치를 보여줍니다.
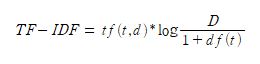
이러한 TF-IDF 방법은 문장내에서의 순서는 고려하지 않게 되며, 이에 따른 문맥 정보가 사라지는 문제가 있습니다. 이에 2013년 구글의 토마스 미코로프 (Tomas Mikolov)는 Word2Vec 이라는 Word Vectors 모델을 공개했습니다. 이는 말 그대로 단어를 벡터로 변환시켜 신경망 구조를 활용하여 그 단어의 ONE-Hot Vector를 입력으로 넣고 주변 단어의 One-Hot Vector 값을 예측하는 방식으로 학습이 이루어지는 개념을 말합니다.
출처: 구글이미지
Word2Vec은 “단어의 매락”을 고려하므로 TF-IDF의 문제를 보완할 수 있는 기법으로 단어의 의미를 잘 파악해내는 것을 확인할 수 있습니다. 이와 같이 자연어처리 (NLP)에는 다양한 기법들이 사용되고 있습니다.
이러한 자연어처리 기술은 다양한 분야에 응용되고 있습니다. 번역 및 맞춤법 검사 뿐 아니라 인공지능 기반의 음성인식 스피커, 챗봇 등에 이미 활용되고 있습니다. 사용자 정서 분석은 마케팅 분야에 주로 사용되는 자연어 처리 응용 기술입니다. 소비자들이 제품에 대한 피드백이나 기업 평가를 SNS에 올리는 사례가 증가하면서 소비자의 문장과 단어를 분석해 만족도를 살피기 위한 자연어 처리 소프트웨어 수요가 기업을 중심으로 확대되고 있습니다. 국내에서는 ETRI가 한국어 전용 언어모델 ‘KorBERT’를 구축해서 구글 검색엔진보다 우수한 성능을 보여줬다고 합니다. 주요 딥러닝 프레임워크인 파이토치 (PyTorch)와 텐서플로우 (Tensorflow) 환경 모두에서 사용 가능하며 오픈 API로 공개했다고 하고, 카카오에서도 딥러닝 기반 형태소 분석기 카이를 오픈 소스로 제공하고 있습니다.
자연어처리의 개념과 기법들에 대한 자세한 내용은 아래 링크에서 확인할 수 있습니다.
* 자연어처리(NLP) 무엇인가...그 기술과 시장은?
https://www.aitimes.kr/news/articleView.html?idxno=15036
* Google Code Archive – Word2Vec
https://code.google.com/archive/p/word2vec/
* Topic Modeling with LSA, PLSA, LDA & lda2Vec
https://medium.com/nanonets/topic-modeling-with-lsa-psla-lda-and-lda2vec-555ff65b0b05
* 출처: ETRI, 엑소브레인 자연어 분석 및 심층질의응답 기술, ETRI, 자연어처리 기술 동향과 데이터의 역할, |
※ 다음 연재는 데이터 분석과정 (데이터 수집, 전처리, 분석)에 대해 소개하고자 합니다.
- 이전글
- 이전글이 없습니다.
- 다음글
- 데이터 마이닝이란 무엇인가?



