 발전기금
발전기금


데이터 마이닝이란 무엇인가?
- 소셜이노베이션융합전공
- 조회수1164
- 2021-03-29

브리태니커 백과사전에서는 데이터 마이닝을 “컴퓨터 과학, 대량의 데이터에서 흥미롭고 유용한 패턴 및 관계를 발견하는 프로세스”로 정의하고 있다. 또한 “데이터셋이라 부르는 대규모 디지털 컬렉션을 분석하기 위해 (신경망 및 머신 러닝과 같은) 통계 및 인공지능 기법과 데이터베이스 관리를 결합하고 비즈니스(보험, 은행, 소매), 과학(천문학, 의학) 및 보안(범죄자와 테러리스트 탐지)에 널리 사용된다”고 기술하고 있다.
(https://www.britannica.com/technology/data-mining)
데이터의 지식 검색(knowledge discovery in data, KDD)이라고도 하는 데이터 마이닝은 대규모의 데이터셋에서 패턴 혹은 중요한 정보를 발견하는 방법이다. 컴퓨터 기술의 발전 덕분에 소위 빅데이터라 불리는 대용량의 자료를 보관하고 처리하는 기술이 발달함에 따라 데이터 마이닝은 수십 년 동안 빠르게 발전했고 이를 바탕으로 기업 혹은 개인이 원자료(raw data)에서 유용한 지식을 찾아낼 수 있게 되었다. 데이터 마이닝 기술의 목적은 크게 두 가지로 나눌 수 있다. 분석하고자 하는 데이터셋의 구조를 살펴보고 이를 설명하는 기술적인(descriptive) 것과 기계 학습 알고리즘을 사용하여 결과를 예측하는 것이다. 특히 정부와 기업에서는 기존에 보유하고 있던 대량의 자료 속에서 그들이 원하는 방식으로 데이터를 구성하고 필터링하는 방법을 통해 다양한 분야에서 활용되고 있다.
데이터 마이닝 프로세스
데이터 마이닝 프로세스에는 대규모 데이터 세트에서 중요한 정보를 추출하기 위해 데이터 수집에서 시각화까지 여러 단계가 포함된다. 위에서 언급한 것처럼 데이터 마이닝 기술은 대상 데이터셋에 대한 설명과 예측을 위해 사용된다. 데이터 사이언티스트는 패턴, 연관성 및 상관 관계를 관찰하여 데이터를 설명하는 한편, 다양한 기법을 통해 데이터를 분류 및 클러스터링하고 이상치를 식별하는 과정을 거친다. 아래는 이러한 과정을 크게 5가지로 요약한 것이다.
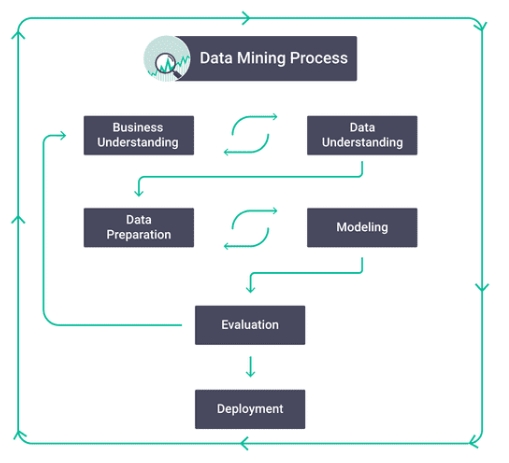
(source: https://www.springboard.com/library/data-science/data-mining/)
1. 수집(Collection): 분석하고자 하는 데이터를 수집하여 사내 서버 또는 클라우드에 서저장 및 관리한다.
2. 이해(Understanding): 비즈니스 분석가나 데이터 과학자는 데이터의 다양한 특성을 검토하고 문제 해결을 위해 보다 심층적인 분석을 수행한다. 이러한 분석은 쿼리, 시각화 등을 통해 다양한 방식으로 자료를 살펴보는 작업을 요구한다.
3. 준비(Preparation): 사용 가능한 데이터 소스가 확인되면 해당 데이터를 클리닝하고 원하는 형식으로 재구성해야 한다. 또한 이전 단계에서 발견한 내용을 바탕으로 추가적인 데이터 탐색이 필요할 수 있다.
4. 모델링(Modeling): 이 단계에서는 준비된 데이터셋에 대한 모델링 기법이 선택된다. 데이터 모델은 데이터베이스에 저장된 다양한 정보 유형 간의 관계를 설명하는 다이어그램과도 같다. 예를 들어, 판매 거래는 고객, 판매자, 판매된 품목 및 지불 방법을 설명하는 관련 데이터 포인트 그룹으로 구분됩니다. 데이터베이스에서 정확하게 저장 및 검색하려면 이러한 각 항목을 체계적으로 설명해야 합니다.
5. 평가(Evaluation): 마지막으로, 모델 결과는 비즈니스 혹은 연구 목표를 기준으로 평가한다. 이 단계에서는 모델링 단계에서 발견된 새로운 패턴 또는 기타 요인으로 모델링 혹은 추가적인 데이터 탐색과 같은 단계로 다시 돌아갈 수 있다.
데이터 마이닝 기법
데이터 마이닝 기법은 매우 다양하게 활용되고 결합되어 응용되고 있으며 아래는 대표적인 기법들을 소개한다.
이상 탐지(Anomaly detection): 비정상적이거나 우려되는 사례나 값을 식별하는 프로세스이다. 가장 일반적인 방법은 평균으로부터 편차를 찾아 탐지하는 것이며, 보다 정교하게 클러스터와 일치하지 않는 인스턴스를 찾거나 데이터 포인트를 가까운 예와 비교하여 기능 값이 크게 구분되는지 확인하는 방법 등이 있다. 예를 들어, 신용카드 회사가 고객의 구매 패턴에 맞지 않는 거래를 식별하여 부정 거래가 아닌지 고객에게 경고하는 데 사용하기도 한다.
예측 모델(predictive models) 구축: 예측 모델링은 과거 데이터를 사용하여 미래의 결과를 예측하는 데 사용할 수 있는 모델 또는 알고리즘을 만들고, 처리 및 검증하는 과정이다. 기업에서는 과거 데이터들을 분석하여 예측 모델을 수립하고 고객의 행동을 예측하고자 한다.
분류(Classification): 분류는 대상 범주 또는 클래스에 할당하는 프로세스이다. 데이터들을 분류하고자 하는 목적은 각 사례에 대한 목표치를 정확하게 예측하는 것이다. 예를 들어, 대출 신청자를 낮은 신용 위험, 중간 위험 또는 높은 신용 위험으로 분류하는 데 활용한다.
군집화(Clustering): 군집화 혹은 클러스터링은 동일한 클래스에서 분류할 수 있는 유사한 속성을 가진 데이터 집합에서 이를 집단화시켜주는 항목을 찾는 것이다. 데이터들의 특성을 통해 이를 묶어주면서 데이터가 가진 특성을 부각시키고 그렇게 군집화된 그룹이 어떻게 구별되는지를 보여준다.
의사결정나무(Decision trees): 의사결정나무는 비모수 기계 학습 모델링 기법을 바탕으로 클래스 레이블 또는 값으로 이어지는 일련의 질문과 같은 형식으로 구성된다. 예를 들어, 은행이 누군가에게 대출을 제공할지 여부를 고려하고 있을 때, 그것은 신청자의 신용위험을 평가하기 위한 질문(평가 혹은 구분기준)의 연속적인 목록을 거치며, 낮음, 보통, 높음의 분류로 구분지어 준다.
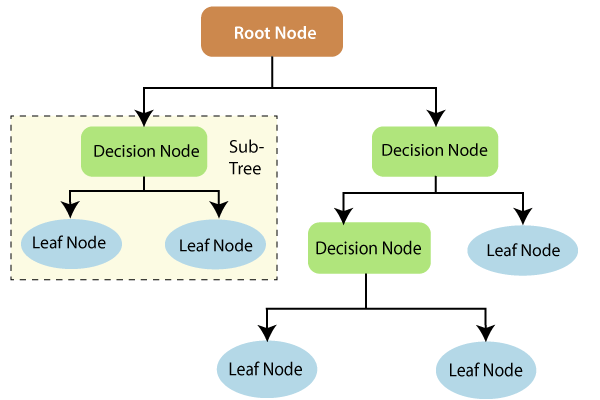
(의사결정나무의 과정)



