



[Research News] Professor Heo Jae-Pil's lab was approved for publishing two papers in AAAI 2023.
- SKKU National Program of Excellence in Software
- Hit916
- 2023-02-01

Two papers from the Visual Computing Laboratory (Professor Heo Jae-pil) have been approved for publication at the AAAI Conference on Artificial Intelligence 2023 (AAAI-23), a top-tier academic conference in the field of artificial intelligence.
Paper #1: "Minority-Oriented Vicinity Expansion with Attentive Aggregation for Video Long-Tailed Recognition"
WonJun Moon, Hyun Seok Seong, and Jae-Pil Heo
Paper #2: “Progressive Few-shot Adaption of Generative Model with Align-free Spatial Correlation” Jongbo Moon*, Hyunjun Kim*, and Jae-Pil Heo (*: equal contribution)
The paper "Minority-Oriented Vicinity Expansion with Attractive Aggregation for Video Long-Tested Recognition" deals with the issue of data imbalance that occurs when video data is acquired.
First of all, we raise additional issues to consider in the video sector, along with data imbalances: 1) weak supervision of video data and 2) the size of traditional video data makes the pre-trained network unsuitable for downstream operations. To fix this error, the paper introduces two Attractive Aggregators and proposes a modified extrapolation and interpolation technique that increases the diversity of classes with fewer data to solve the data imbalance problem. Experiments have shown that the proposed method has resulted in consistent performance improvements in benchmarks. In addition, experiments have confirmed the importance of two issues that we have argued should be addressed simultaneously with data imbalance through ablation studies.
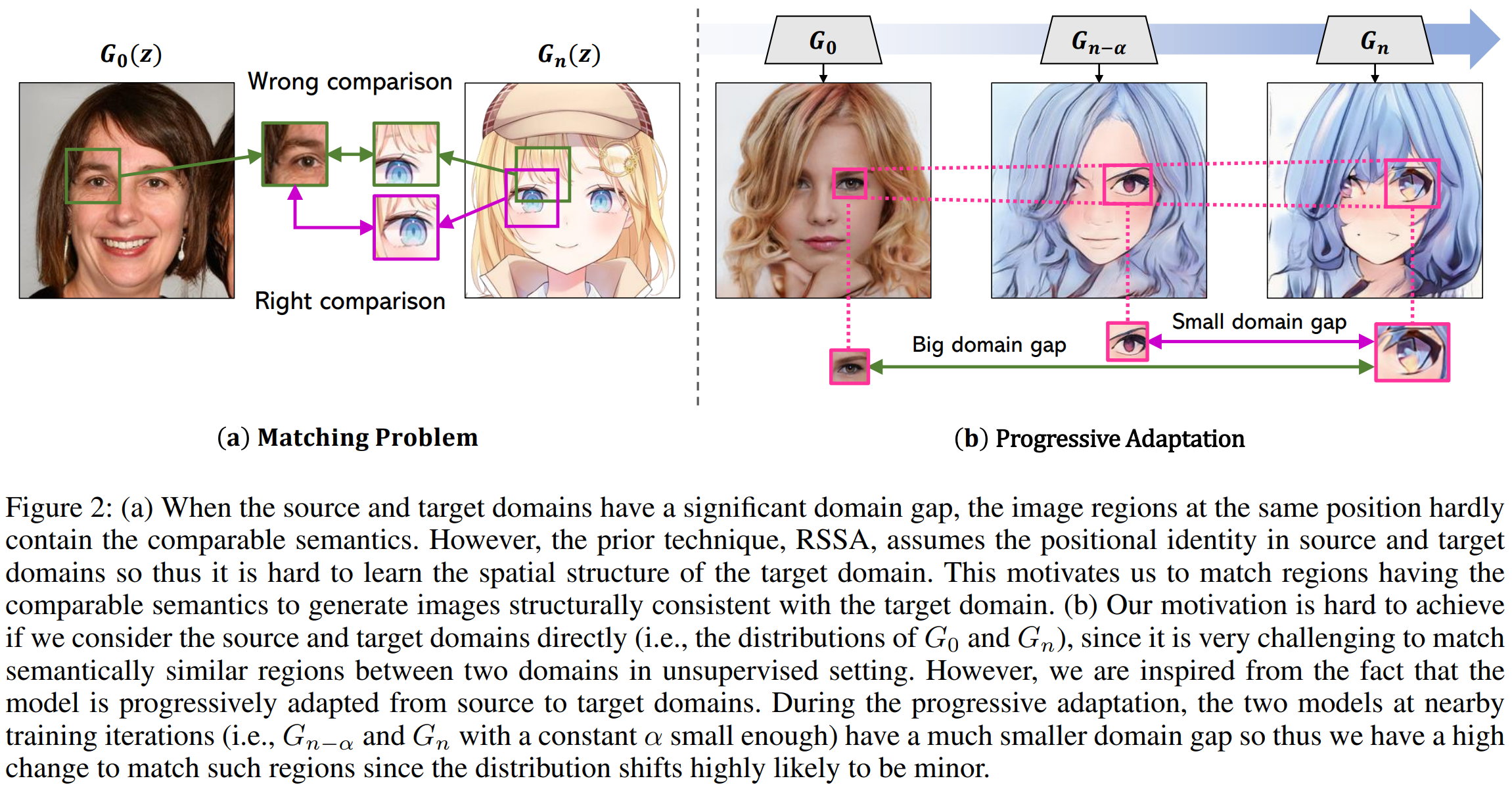
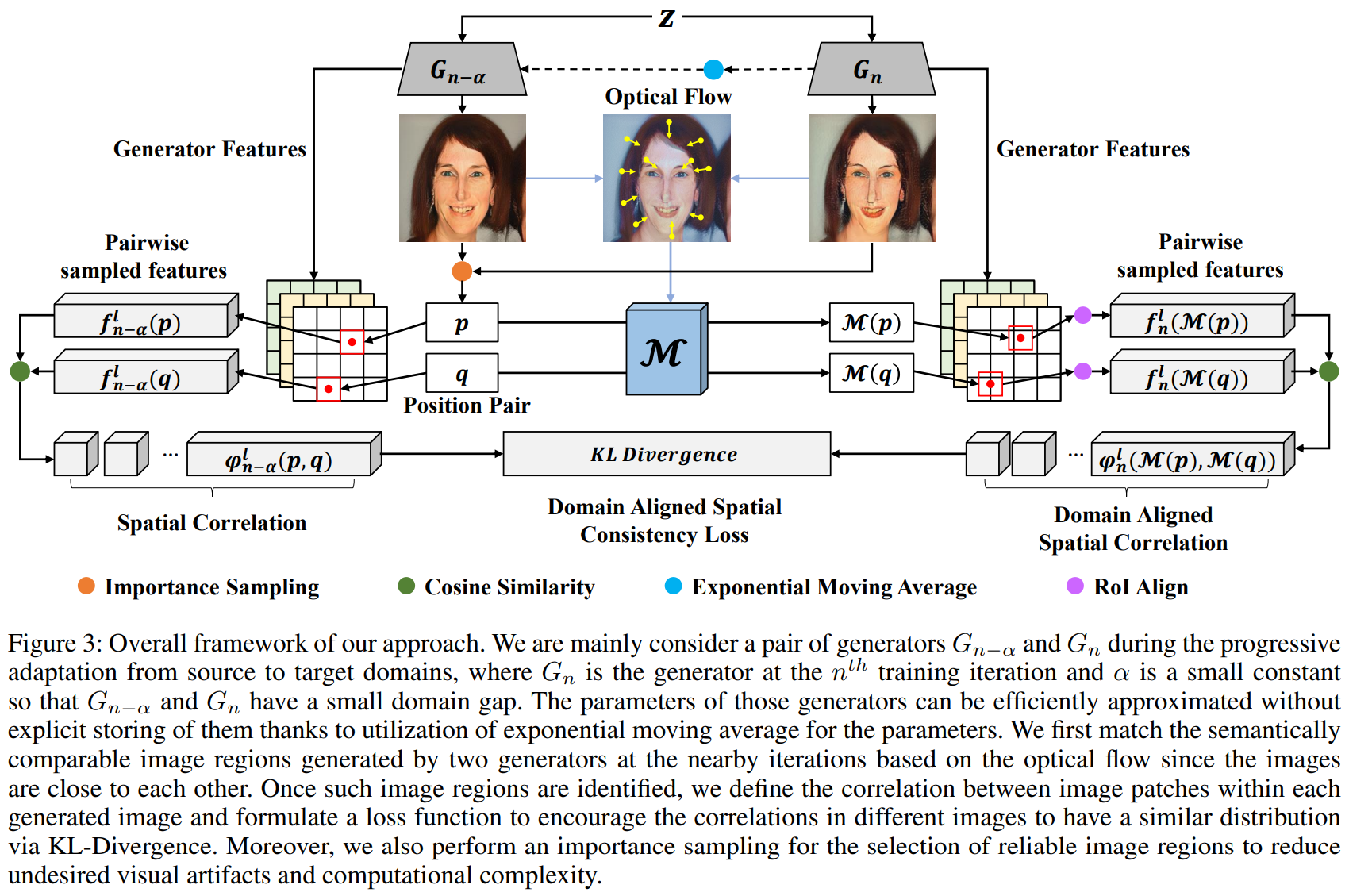
The "Progressive Few-shot Adaptation of Generative Model with Align-free Spatial Correlation" paper addresses the problem of adapting the GANs model with only a very small number of target domain images. Since the use of common methods such as fine-tuning is vulnerable to mode-collapse, methods for learning that the images generated by the Source and Target models respectively maintain a relative distance have been recently studied. However, there is a problem that 1) the method of measuring the distance with the overall feature of the image loses the detailed feature of the Source model, and 2) the method of learning to maintain the consistency of the image patch unit feature loses the structural characteristic of the target domain. To fix this error, the paper aimed to adaptation that reflects the structural characteristics of the target domain through comparisons between meaningful areas (e.g., comparisons between human and character eye areas) while preserving the detailed features of the Source model. To this end, we proposed 1) Progressive Adaptation that reduces Domain Gap, 2) Align-free Spatial Correlation for comparison between meaningful areas, and 3) Importance Sampling methods. It was confirmed that the proposed method through various experiments showed excellent performance in quantitative and qualitative evaluations, especially in human evaluations.
[About paper #1]
Minority-Oriented Vicinity Expansion with Attentive Aggregation for Video Long-Tailed Recognition
WonJun Moon, Hyun Seok Seong, and Jae-Pil Heo
Thirty-Seventh AAAI Conference on Artificial Intelligence (AAAI), 2023
Abstract:
A dramatic increase in real-world video volume with extremely diverse and emerging topics naturally forms a long-tailed video distribution in terms of their categories, and it spotlights the need for Video Long-Tailed Recognition (VLTR). In this work, we summarize the challenges in VLTR and explore how to overcome them. The challenges are: (1) it is impractical to re-train the whole model for high-quality features, (2) acquiring frame-wise labels requires extensive cost, and (3) long-tailed data triggers biased training. Yet, most existing works for VLTR unavoidably utilize image-level features extracted from pretrained models which are task-irrelevant, and learn by video-level labels. Therefore, to deal with such (1) task-irrelevant features and (2) video-level labels, we introduce two complementary learnable feature aggregators. Learnable layers in each aggregator are to produce task-relevant representations, and each aggregator is to assemble the snippet-wise knowledge into a video representative. Then, we propose Minority-Oriented Vicinity Expansion (MOVE) that explicitly leverages the class frequency into approximating the vicinity distributions to alleviate (3) biased training. By combining these solutions, our approach achieves state-of-the-art results on large-scale VideoLT and synthetically induced Imbalanced-MiniKinetics200. With VideoLT features from ResNet-50, it attains 18% and 58% relative improvements on head and tail classes over the previous state-of-the-art method, respectively.


[About paper #2]
Progressive Few-shot Adaption of Generative Model with Align-free Spatial Correlation
Jongbo Moon*, Hyunjun Kim*, and Jae-Pil Heo (*: equal contribution)
Thirty-Seventh AAAI Conference on Artificial Intelligence (AAAI), 2023
Abstract:
In few-shot generative model adaptation, the model for target domain is prone to the mode-collapse. Recent studies attempted to mitigate the problem by matching the relationship among samples generated from the same latent codes in source and target domains. The objective is further extended to image patch-level to transfer the spatial correlation within an instance. However, the patch-level approach assumes the consistency of spatial structure between source and target domains. For example, the positions of eyes in two domains are almost identical. Thus, it can bring visual artifacts if source and target domain images are not nicely aligned. In this paper, we propose a few-shot generative model adaptation method free from such assumption, based on a motivation that generative models are progressively adapting from the source domain to the target domain. Such progressive changes allow us to identify semantically coherent image regions between instances generated by models at a neighboring training iteration to consider the spatial correlation. We also propose an importance-based patch selection strategy to reduce the complexity of patch-level correlation matching. Our method shows the state-of-the-art few-shot domain adaptation performance in the qualitative and quantitative evaluations.
Heo Jae-Pil | jaepilheo@skku.edu | Visual Computing Lab | https://sites.google.com/site/vclabskku/